토비의 스프링 정리
토비의 스프링 - 9.3 애플리케이션 아키텍처
ksb-dev
2022. 10. 27. 22:23
9.3.1 아키텍처와 SoC
- 지금까지 주로 오브젝트 레벨에서 관심, 성격, 책임의 분리를 진행했음
- 이 원리는 아키텍처 레벨에서도 동일하게 적용할 수 있음
- 데이터 액세스 로직을 담당하는 DAO들만 하나의 단위로 묶고, 비즈니스 서비스만 하나의 단위로 묶을 수 있음
- 💡 서비스 오브젝트들은 POJO로 만들어짐. 밑에서 나오지만, 서비스 계층과 기반 서비스 계층은 다름
- 성격이 다른 것은 아키텍처 레벨에서 분리하면 독자적인 개발 및 테스트가 가능해 개발과 변경이 모두 빨라질 수 있음
- 이렇게 책임과 성격이 다른 것을 크게 그룹으로 만들어 분리하는 아키텍처를 계층형 아키텍처(Layered Architecture) 또는 멀티 티어 아키텍처라고 함
- 보통 웹 기반의 엔터프라이즈 애플리케이션은 세 개의 계층을 갖는다고 해서 3계층 애플리케이션이라고도 함
9.3.2 3계층 아키텍처와 수직 계층
- 3계층 아키텍처는 데이터 액세스, 서비스, 프레젠테이션 계층으로 구분함
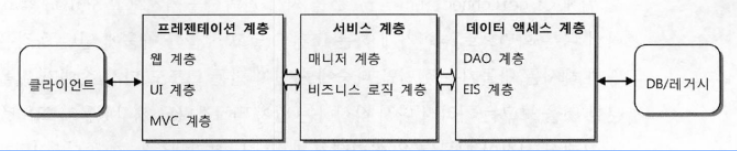
- 데이터 액세스 계층
- 데이터 액세스 계층은 DAO 계층이라고도 불림
- 또한 데이터 액세스 계층은 DB 외에도 ERP, 레거시 시스템, 메인프레임들에 접근하는 역할을 하기 때문에 EIS(Enterprise Information System) 계층이라고도 함
- 또, 외부 시스템을 호출해서 서비스를 이용하는 것은 기반(Infrastructure) 계층으로 따로 분류하기도 함
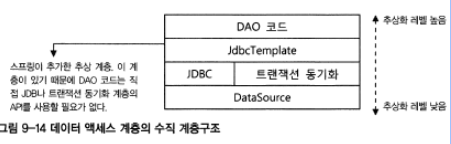
- 데이터 액세스 계층은 사용 기술에 따라 세분화된 계층으로 구분할 수 있음
- 세분화된 계층은 추상화 수준에 따른 구분이기 때문에 수직적인 계층이라고도 함
- 새로운 추상화된 계층을 추가하면 코드에 지대한 영향을 끼치기 때문에 신중해야 함
- 서비스 계층
- 서비스 계층은 이상적인 POJO로 작성됨
- POJO로 만든다면 비즈니스 로직의 핵심을 잘 담아내고, 이를 유연하게 확장할 수 있음
- 서비스 계층은 특별한 경우가 아니라면 추상화 수직 계층구조를 가질 필요가 없음
- 기술 API를 직접 다루지 않기 때문에 추상화가 필요 없기 때문임
- 비즈니스 로직을 담은 서비스 계층과 엔터프라이즈 서비스를 제공하는 기반 서비스 계층을 잘 구분해야 함
- 일반적으로 서비스 계층에서 기반 서비스 계층의 API를 호출해 이용함
- 반대로 서비스 계층의 코드를 기반 서비스 계층에서 사용할 수 도 있음
- 스케줄링이 대표적인 예시임
- 정해진 시간에 백그라운드 서비스가 필요할 때 기반 서비스 계층에서 서비스 계층의 오브젝트를 이용하게 할 수 있음
- 원칙적으로 서비스 계층 코드가 기반 서비스 계층의 구현에 종속되지 않도록 인터페이스를 이용해야 함
- 또는 AOP를 이용해 서비스 계층의 코드를 침범하지 않고 부가기능을 추가하는 방법을 활용해야 함
- 이상적인 서비스 계층은 데이터 액세스 및 프레젠테이션 계층이 변경되더라도 그대로 유지할 수 있어야 함

- 프레젠테이션 계층
- 가장 복잡한 계층임
- 프레젠테이션 계층은 매우 다양한 기술과 프레임워크의 조합을 가질 수 있음
- 엔터프라이즈 애플리케이션의 프레젠테이션 계층은 클라이언트의 종류와 상관없이 HTTP 프로토콜을 사용하는 서블릿이 바탕이 됨
- 프레젠테이션 계층은 다른 계층과 달리 클라이언트까지 그 범위를 확장시킬 수 있음
- 프레젠테이션 로직이 클라이언트로 이동된 대표적인 아키텍처가 RIA(Rich Internet Architecture)와 SOFEA(Service Oriented Front End Architecture)가 있음
9.3.3 계층형 아키텍처 설계의 원칙
- 각 계층은 높은 응집도와 낮은 결합도를 가져야 함
- 즉, 자신의 역할에만 충실하고 관련 기술이 아닌 API는 사용해선 안됨
- 자신의 역할에 충실하면, 필요한 그 밖의 작업은 인터페이스를 통해 다른 계층에 요청됨
- 아래 코드는 ResulteSet을 반환하기 때문에, JDBC에 의존적임
public ResulteSet findUsersByName(String name) throw SQLException;- 또한, 체크 예외로 인해 서비스 계층에서 SQLException을 해석해야 하기 때문에 강한 결합이 발생함
- 아래 코드와 같이 단순한 오브젝트 형태로 전달해야 함
public List<User> findUsersByName(String name) throw DataAccessException;- 또한, 런타임 예외로 던져야 함
- 흔히 저지르는 실수 중 하나는 프레젠테이션 계층의 오브젝트 형태 그대로 서비스 계층에 전달하는 것임
- 서블릿의 HttpServletRequest나 HttpSession 같은 타입을 파라미터로 사용하면 안됨
- 계층 경계를 넘어갈 때는 반드시 특정 계층에 종속되지 않는 오브젝트 형태로 변환해야 함
- 스프링의 DI는 기본적으로 오브젝트 사이의 관계를 다룸
- 따라서 계층 사이의 경계나 그 관계에 직접적인 관여를 하지 않음
- 즉, 계층을 구분하지 않기 때문에 빈 사이의 의존관계를 만들 때 주의해야 함
- 한 계층에서만 사용하도록 만든 빈을 다른 계층에서 사용하면 안된다는 뜻임
9.3.4 DB/SQL 중심의 로직 구현 방식
- 데이터 중심 구조임
- 데이터 중심 구조는 하나의 업무 트랜잭션에 모든 계층의 코드가 종속되는 경향이 있는 특징이 있음
- 검색조건은 SQL로 만들어지고, 업무의 내용이 바뀌면 모든 계층의 코드가 함께 변경됨
- 검색 로직의 조건이 많고 복잡해지면 그만큼 복잡한 SQL이 만들어짐
- 대부분의 코드는 대응되는 작업 단위에 1:1로 매핑됨
- 이런 방식은 자바 코드를 DB와 웹 화면을 연결해주는 단순한 인터페이스 도구로 전락시키는 것임
- 항상 SQL에 결과가 종속되기 때문에, SQL에 변화가 발생하면 같이 변경되야 하기 때문에 강한 결합을 갖음
- 또한, SQL이나 저장 프로지저에 담긴 로직은 테스트하기 힘듦
9.3.5 거대한 서비스 계층 방식
- DB에 많은 로직을 두는 개발 방법의 단점을 피하면서 애플리케이션 코드의 비중을 높이는 방법임
- 복잡한 SQL을 피하면서, 주요 로직은 서비스 계층의 코드에서 처리하도록 함
- DAO가 돌려준 정보를 분석, 가공하면서 비즈니스 로직을 적용하는 것은 서비스 계층 코드의 책임이 됨
- 상대적으로 단순한 DAO 로직을 사용하고, 비즈니스 로직의 대부분을 서비스 계층에 집중하는 방법을 거대 서비스 계층(Fat Service Layer)이라 하는 것임
- 거대 서비스 계층은 애플리케이션 코드에 비즈니스 로직이 담겨있기 때문에 자바의 언어의 장점을 활용해 로직을 구현할 수 있고, 테스트하기 용이하다는 장점이 있음
- 또한 각 단위별로 개발을 할 수 있고, SQL이 복잡하지 않고 프레젠테이션 계층의 뷰와 1:1로 매핑되지 않아도 되기 때문에 일부 DAO 코드는 여러 비즈니스 로직에서 공유할 수 있음
- 하지만 데이터 액세스 계층의 SQL은 서비스 계층의 비즈니스 로직의 필요에 따라 만들어지기 쉽기 때문에 강한 결합을 여전히 가지고 있음
- 또한 서비스 계층의 코드는 여전히 업무 트랜잭션 단위로 만들어지기 때문에 DAO를 공유할 수 있는 것을 제외하면 코드의 중복이 적지 않게 발생됨
- 각 단위별로 개발을 할 수 있다는 장점은 단점이 될 수 있음
- 개발자마다 개발 성향이 다를 수 있기 때문에 잘못하면 데이터 중심 구조보다 더 다루기 힘든 코드가 만들어질 수 있음
9.3.6 오브젝트 중심 아키텍처
- 오브젝트 중심 아키텍처가 데이터 중심 아키텍처와 다른 가장 큰 특징은 도메인 모델을 반영하는 오브젝트 구조를 만들어두고, 그것을 각 계층 사이에서 정보를 전송하는데 사용하는 것임
- 오브젝트 중심 아키텍처는 도메인 모델을 오브젝트 모델로 활용함
- 대개 도메인 모델은 DB의 엔티티 설계에도 반영되기 때문에 관계형 DB의 엔티티 구조와도 유사한 형태일 가능성이 높음
- 오브젝트를 만들고 오브젝트 구조 안에 정보를 담아서 각 계층 사이에 전달하게 하는것이 오브젝트 중심 아키텍처임
- 데이터 중심 아키텍처
- 1:N 관계로 Category와 Product가 있음
필드명 타입 설정 CategoryId int Primary Key Description varchar(100)
이 두 개의 정보를 가져오는 방법은 JOIN을 통해 2차원 구조의 정보를 가져와야 함필드명 타입 설정 ProductId int Primary key Name varchar(100) Price int CategoryId int Foregin Key(Category)
Select c.categoryid , c.description, p.productid, p.name, p.price,
FROM product p
JOIN category c
ON p.categoryid= c.categoryid- SQL을 통해 가져온 정보를 맵에 담아야 하지만, 일일이 필드 이름을 기억해야 하기 때문에 불편함
while(rs.next()){
Map<String,Object> resMap = new HashMap<String, Object>();
resMap.put(“categoryid”,rs.getString(1));
resMap.put(“description“, rs.getString(2));
…
list.add(resMap);
}- 서비스 계층에 전달되는 List<Map<String, Object>> 타입 이지만, 타입만 봐서는 안에 어떤 내용이 담겨져 있는지 확인할 수 없음
- 오브젝트 중심
- 도메인 오브젝트는 데이터 중심 처럼 일일이 맵에 저장하지 않고, 오브젝트의 레퍼런스 변수를 통해 값을 가져옴
public class Category{
int categoryid;
String description;
Set<Product> products; //1:N이기 때문에 컬렉션을 이용해 저장
…
}
public class Product{
int productid;
Stringname;
int price;
Category category; //레퍼런스 변수로 값을 가져옴
…
}- 도메인 모델을 따르는 오브젝트 구조를 한 번만 만들면 작업이 수월해짐
- 애플리케이션에서 사용되는 정보가 도메인 모델구조를 반영해서 만들어진 오브젝트안에 담김
- 도메인 모델은 전 계층에서 일관된 구조를 유지한채 사용할 수 있음
- 데이터 중심 방식과 달리 재사용 가능한 메소드를 만들어 사용하기 쉬움
public int calcTotalOfProductPrice(Category cate){
int sum=0;
//Category안에 포함된 Product를 간단히 가져올 수 있음
for(Product prd:cate.getProduct())
sum+=prd.getPrice();
return sum;
}- 단, 도메인 오브젝트에 단점이 있음
- 최적화된 SQL을 사용하는 데이터 중심 아키텍처보다 성능이 좀 떨어질 수 있음
- 하나의 오브젝트 안에 필드의 개수가 많아지면 사용되지 않는 필드가 있을 수 있기 때문임
- 사용하지 않는 필드를 Null로 만들면 나중에 NullPointerException을 만날 수 있음
- 성능이 떨어지는 문제는 지연된 로딩(Lazy Loading)을 통해 해결할 수 있음
- 지연된 로딩이란, 최소한의 오브젝트 정보만 읽어두고 나중에 추가적인 정보가 필요할 경우 동적으로 DB에서 다시 읽어오는 방법임
- JPA, JDO, 하이버네이트, TopLink와 같은 오브젝트/RDB 매핑(ORM) 기술은 지연된 로딩을 지원하기 때문에 ORM 기술을 사용하는 것을 권장함
9.3.7 빈약한 도메인 오브젝트
- 도메인 오브젝트는 자바 오브젝트임
- 오브젝트는 정보 저장 뿐만이 아니라, 내부의 정보를 이용하는 기능도 함께 가지고 있어야 함
- 단순히 정보만 담겨있는 오브젝트를 빈약한(Anemic) 오브젝트라 함
- 도메인 오브젝트 기능이라 하면 도메인 오브젝트의 비즈니스 로직이라 볼 수 있음
- 빈약한도메인 오브젝트의 경우 비즈니스 로직이 전부 서비스 계층에 있기 때문에 거대 서비스 계층구조와 비슷함
- 도메인 오브젝트는 독립적으로 존재하면서 일관된 구조의 정보를 담아서 전달하는데만 사용됨
- SQL에 의존적인 데이터 방식보다 유연하고 간결하지만, 서비스 계층의 메소드에 대부분의 비즈니스 로직이 있기 때문에 재사용성이 떨어지고 중복의 문제가 발생하기 쉬움
9.3.8 풍성한 도메인 오브젝트 방식
- 풍성한 도메인 오브젝트(Rich Domain Object)는 영리한 도메인 오브젝트(Smart domain Object) 방식이라고도 함
- 어떤 비즈니스 로직은 특정 도메인 오브젝트와 깊은 관계가 있을 수 있음
- 해당 로직을 도메인 오브젝트에 넣고, 서비스 계층의 비스니스 로직에서 재사용하도록 함
public class Category{
List<Product> products;
...
public int calcTotalOfProductPrice(){ //파라미터가 필요 없음
int sum=0;
for(Product prd:this.products()) //내부 정보를 활용해 로직 수행
sum+=prd.getPrice();
return sum;
}
}- 데이터와 데이터를 사용하는 로직을 모아두기 때문에 응집도가 높음
- 다른 계층의 기능을 사용하기 위해서는 빈을 등록되어서 DI 받아야 함
- 하지만, 도메인 모델은 일반적으로 빈으로 등록할 수 없음
- 도메인 오브젝트는 매우 짧은 생명주기를 가지며 요청에 의해서만 나타나고 사라져야하기 때문임
- 기능을 제공하는 오브젝트와 제공받는 오브젝트 둘 다 빈으로 등록해야 스프링이 관리할 수 있기 때문에 DI가 가능함
- 때문에, 3계층에서 도메인을 사용할 수 있지만 반대는 불가능 함
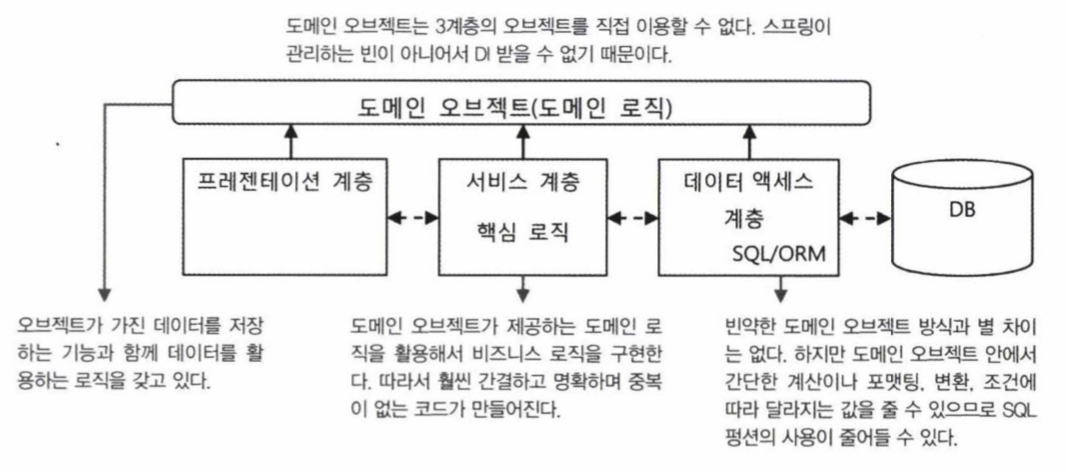
9.3.9 도메인 계층 방식
- 지금까지 도메인 방식은 한계가 있음
- 도메인 오브젝트에서 변경된 정보가 다시 DB 등에 반영이 되려면 서비스 계층 오브젝트의 부가적인 작업이 필요함
- 도메인 오브젝트가 기존 3계층과 같이 하나의 계층을 이루게 하여 역할 및 비중을 극대화 하는 방식을 도메인 계층 방식이라 함
- 하나의 독립적인 계층을 서비스 계층과 데이터 액세스 계층 사이에 존재하게 함
- 도메인 계층에는 두 가지 특징이 있음
- 도메인 종속적인 비즈니스 로직의 처리는 서비스 계층이 아닌 도메인 계층에서 진행됨
- 도메인 오브젝트가 데이터 액세스 계층이나 기반 계층의 기능을 직접 활용할 수 있음
- 이러한 특징을 적용하기 위해 도메인 계층을 빈으로 등록해야 함
- AspectJ AOP를 활용하면 클래스의 생성자가 호출되면서 빈이 아닌 일반 오브젝트에도 AOP 부가기능을 적용할 수 있음
- 부가기능은 수정자 메소드나 DI용 애노테이션을 참고해서 DI 가능한 대상을 스프링 컨테이너에 찾아 DI 해주는 기능임
- 즉, 일반 오브젝트에 대한 DI 서비스가 일종의 AOP 부가기능임
- 도메인 계층에 AspectJ를 사용해서 빈으로 등록하게 할 수 있음
- 도메인 오브젝트는 계층을 이루기 전에는 전 계층에서 사용할 수 있는 정보 전달 도구 였음
- 이 도메인을 독립적인 도메인 계층으로 적용할 때 두 가지 고려사항이 있음
- 여전히 모든 계층에서 도메인 오브젝트를 사용하도록 함
- 모든 계층에서 도메인을 사용하도록 하면 주의해야 할 점이 있음
- 도메인 계층에서 도메인에는 일반적인 정보 뿐만이 아니라, 정보를 조작할 수 있는 기능이 추가되었음
- 때문에, 가이드 라인없이 잘못 사용하면 큰 문제를 발생 시킬 수 있음
- 도메인 오브젝트는 도메인 계층을 벗어나지 못하게 함
- 별도의 준비된 정보 전달용 오브젝트인 DTO(Data Transfer Object)에 정보를 복사해서 전달하도록 함
- 읽기 전용으로 만들어진 DTO는 기능을 가지지 않기 때문에 안전함
- 여전히 모든 계층에서 도메인 오브젝트를 사용하도록 함
- 도메인 계층 구조
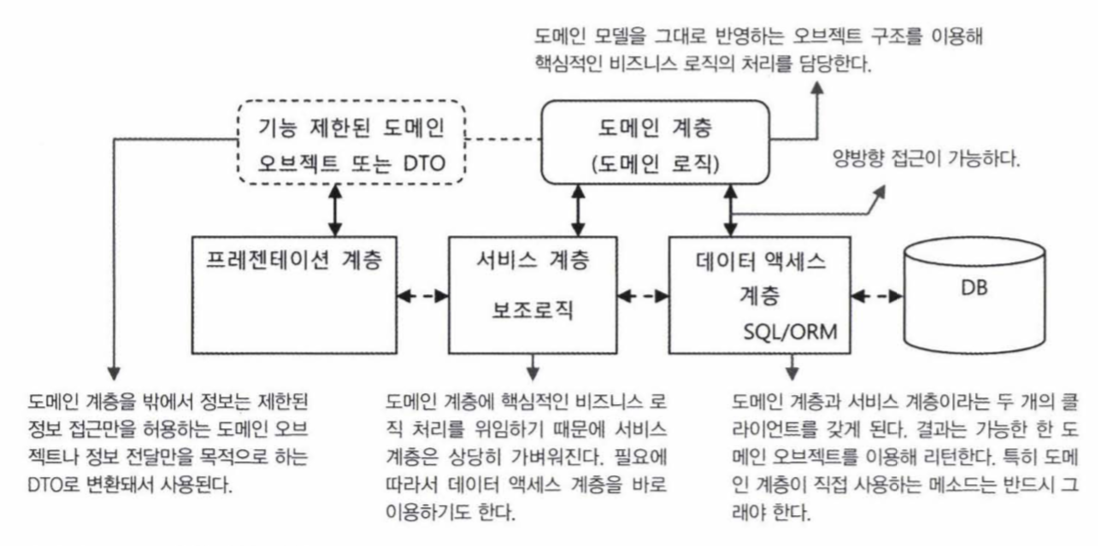
- 도메인 계층을 사용하는 것은 AspectJ 사용을 강제하기 때문에 제약이 많고, 만들기 불편함
- 이런 제약 및 불편을 감수하더라도 도메인 계층 방식을 택해야 하는 경우는 매우 복잡하고 변경이 잦은 도메인을 가졌을 때임
- 도메인 오브젝트 변경에 대한 빠른 대응 및 변경을 하기 위해 도메인 계층을 사용함
- 도메인 계층은 응집도가 높기 때문에 단위 테스트를 만들기 쉬움
- 반면에 복잡하지 않은 애플리케이션의 경우 과도한 부담을 가지게 할 수 있음
9.3.10 DTO와 리포트 쿼리
- 도메인 계층 방식의 경우 도메인 계층을 벗어난 정보를 DTO에 담아 사용함
- 그 외에도 DTO의 사용이 꼭 필요할 때가 있음
- 대표적인 예시가 리포트 쿼리(Report Query)임
- DB 쿼리의 실행 결과인 리포트 쿼리를 DTO에 담아서 사용함
- DB 쿼리의 실행 결과를 담을 적정한 도메인 오브젝트를 찾기 힘들기 때문에 DTO를 만들어 사용함
9.3.11 계층형 아키텍처
- 3계층 구조는 엔터프라이즈 애플리케이션에서 가장 많이 사용되는 구조임
- 스프링의 주요 모듈과 기술을 살펴보면 3계층 구조에 적합하도록 설계되어 있음
- 하지만, 계층을 통합해도 됨
- 데이터 액세스 계층과 서비스 계층을 통합하거나, 서비스 계층과 프레젠테이션 계층을 통합해서 사용해도 큰 문제는 없음
- 프레젠테이션 계층은 보통 MVC라는 이름으로 잘 알려진 패턴 또는 아키텍처를 주로 사용함
- 스프링의 대표적인 프레젠테이션 기술도 SpringMVC라는 이름을 갖고 있고, 이름처럼 MVC 패턴을 지원하게 되어 있음
- 스프링은 이 MVC 중 가장 부담을 많이 지고 있는 컨트롤에(C)에 해당하는 부분을 또 다시 세분화해서 여러 단계의 오브젝트로 만들 수 있도록 설계되어 있음
- 프레젠테이션 계층은 특히 그 세분화된 경계를 애플리케이션이 배치된 서버를떠나서 클라이언트까지 확장하기도 함
- SOFEA라 불리는 아키텍처는 프레젠테이션 계층의 코드가 서버에서 클라이언트로 다운로드돼서 클라이언트 장치 안에서 프레젠테이션 기능이 수행됨
- 스프링을 처음 학습하고 도입하는 입장이라면 프레젠 테이션 계층은 SpringMVC를 이용하고, 서비스 계층은 POJO로 구현하면서 트랜잭션 AOP를 적용하고, 데이터 액세스 계층은 ORM 기술을 활용하는 것이 좋음
- 스프링이 익숙해 지면 다양한 방식으로 계층 구조의 통합과 분산을 시도하도록 해야함
9.3.12 정보 전송 아키텍처
- 처음에는 빈약한 도메인 오브젝트를 사용하는것이 가장 쉬움
- 도메인 오브젝트를 사용해 애플리케이션의 정보를 일관된 형태로 유지하는 것이 스프링에 가장 잘 들어맞는 방식임
- DB와 SQL에 많은 비즈니스 로직을 담고있는 레거시 시스템을 스프링으로 전환하는 경우라면, 일단 데이터 중심의 아키텍처를 사용해도 무방함
- 레거지 시스템을 가져오되 새롭게 처음부터 시작할 수 있다면 도메인 오브젝트 중심의 아키텍처 적용이 바람직함
- 도메인 계층을 적용하는 경우 AspectJ를 사용해야 하기 때문에 신중히 결정해야 함
9.3.13 상태 관리와 빈 스코프
- 서버기반 애플리케이션은 지속적으로 유지되는 상태를 갖지 않는 Stateless 특징이 있음
- 하지만 어떤 식으로든 애플리케이션의 상태와 장시간 진행되는 작업 정보는 유지돼야 함
- 이를 위해 웹 클라이언트에 URL, 파라미터, 폼 히든 필드, 쿠키 등을 이용해 상태정보 또는 서버에 저장된 상태정보에 키 값 등을 전달해야 함
- HTTP 세션과 같은 서블릿 컨테이너가 제공하는 저장공간을 활용하기도 함
- 스프링은 기본적으로 상태가 유지되지 않는 빈과 스코프틑 사용하도록 권장함
- 단, 애플리케이션의 특징에 따라 상태 유지 스타일의 애플리케이션을 만들 수 도 있음
9.3.14 서드파티 프레임워크, 라이브러리 적용
- 스프링은 거의 대부분의 자바 표준 기술과 함께 사용될 수 있음
- 표준 기술 외에도 많이 사용되는 오픈소스 프레임워크, 라이브러리, 사용 제품 등 도 함께 사용될 수 있음
- 이러한 기술을 스프링과 함께 사용할 때 먼저 스프링이 공식적으로 지원하는지 살펴봐야 함
- 스프링이 지원하는 기술이란 의미는 네 가지로 표현할 수 있음
- 해당 기술을 스프링의 DI 패턴을 따라 사용할 수 있음
- 프레임워크나 라이브러리의 핵심 클래스가 빈으로 등록하고 사용할 수 있도록 팩토리 빈을 제공한다는 뜻임
- 빈으로 등록할 수 있다면 프로퍼티를 통해 세부 조정을 할 수 있음
- 또, 스프링이 제공하는 추상화 서비스를 통해 다른 리소스에 투명하게 접근할 수 있음
- 만약 핵심 API나 클래스가 만들어져 있지 않는 경우 빈으로 사용될 수 있게 팩토리 빈을 도입해야 함
- 스프링의 서비스 추상화가 적용되었음
- 서비스 추상화는 일관된 접근 방법을 제공하는 것임
- 일관된 접근 방법 통해 서드파티 프레임워크를 적용할 수 있을 뿐만이 아니라 필요에 따라 호환 가능한 기술로 쉽게 교체할 수 있음
- 또한, 서비스 추상화는 유연한 설정과 테스트를 용이하게 해줌
- 스프링이 지지하는 프로그래밍 모델을 적용했음
- 스프링이 지지하는 프로그래밍 모델이 적용된 대표적인 예는 스프링의 데이터 액세스 기술에 대한 일관된 예외 적용임
- 스프링의 데이터 액세스 지원 기능을 사용하면 데이터 액세스 기술에 상관없이 일관된 예외 계층구조를 따라 예외가 던져짐
- 독립적인 데이터 액세스 예외를 추상화하고, 런타임 예외를 던지는 스프링의 개발 철학이 적용된 것임
- 이를 통해, 서비스 계층이 데이터 액세스 계층의 기술에 종속되지 않도록
- 💡 체크 예외를 던지면 서비스 계층에서 해당 예외를 분석하는 코드가 있어야 하므로, 종속적이게 됨
- 템플릿/콜백이 지원됨
- 템플릿/콜백은 반복적으로 등장하고 판에 박힌 코드를 간편하게 재사용할 수 있도록 하는 것임
- 대표적인 예시가 try/catch/finally임
- 대부분의 템플릿 클래스는 빈으로 등록해서 필요한 빈에서 DI 받아 사용할 수 있음
- 해당 기술을 스프링의 DI 패턴을 따라 사용할 수 있음
- 스프링은 모든 기술과 프레임워크를 지원하지 않지만, 잘만 사용하면 어떤 기술이든지 손쉽게 적용할 수 있음
- 때로 AOP나 예외 전환을 적용할 수도 있음
- 예외 변환은 종종 AOP를 통해 이뤄짐
- 특정 예외가 던져졌을 때에 대한 포인트 컷을 만들어두고 어드바이스에서 예외를 추상화된 런타임 예외로 바꿔서 다시 던져주면 됨