한 프로젝트에서 테스트케이스를 작성하는데, findAll에서 에러가 발생했습니다.
member 객체를 mock으로 생성해서 발생하는 문제였습니다.
mock객체는 가짜 객체입니다.

mock으로 객체를 만들면 실제 값은 null입니다.
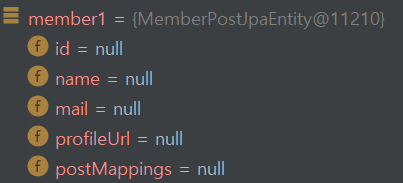
mock객체의 모든 값은 null이지만
when으로 선언하면,
Mockito가 프록시 방식으로 실제 동작할 때 값 대체합니다.

💡 여기서 프록시 방식이란, 요청을 가로채서 동작하는 방식을 의미합니다.
저는 테스트케이스 내부에 아래와 같이 영속성에 추가해줬습니다.
그러면, 모든 값이 null인 member mock 객체가 영속성 컨텍스트에 저장됩니다.


💡 entityManager를 통해 영속성 컨텍스트에 접근할 수 있습니다.
아래 테스트케이스를 보면
findById는 제대로 동작하는데,
findAll에서 에러가 발생하는 것을 볼 수 있습니다.

왜 그럴까요?
JPA를 사용하면 기본적으로 사용할 수 있는 메소드들이 있습니다.
save(), findById(), findAll() 등이 그것입니다.
이 메소드들은 JPA의 구현체인 SimpleJpaRepository에 정의되어 있습니다.
실제 save()와 같은 기본 제공 메소드들을 사용하게 되면,
이 클래스 내부의 메소드들이 동작합니다.
SimpleJpaRepository의 findById()는 아래와 같이 정의되어 있습니다.

자세히 읽어보면 em.find()를 통해 영속성 컨텍스트에서 값을 가져오고 있습니다.
그림을 나타내면 다음과 같습니다.

findById는 단순히 영속성 컨텍스트에서 값을 조회하기 때문에 문제가 발생하지 않습니다.
하지만 findAll()은 다릅니다.
findAll()은 아래와 같이 정의되어 있습니다.

getQuery()를 가보면 아래와 같이 정의되어 있습니다.

코드를 보시면 Criteria를 만들고 있습니다.
Criteria를 만드는 이유는 더티체킹(Dirty Checking) 때문입니다.
실제 모든 수정 정보를 바로 DB에 적용하지 않는 JPA 특성상,
영속성 컨텍스트에 남아있는 값이 실제 DB에 저장된 값과 다를 수 있습니다.
때문에, 전체를 조회하는 findAll()은 값을 가져오기 전에
영속성 컨텍스트와 DB를 동기화 하는 flush()가 동작합니다.

지금 Id가 null인 객체를 flush()로 DB에 저장(insert)하려고 하고 있습니다.
제약조건 상, Id는 null이 될 수 없습니다.
이러한 이유로 에러가 발생하는 것입니다.
테스트케이스를 오류를 자세히 보면 null을 insert하기 때문에 발생하는 것을 확인할 수 있습니다.


요약하면 아래와 같습니다.
findById()는 영속성 컨텍스트에서 데이터를 가져온다.
findAll()은 영속성 컨텍스트 내부의 값을 **flush()**한 후, 데이터를 가져온다.
'삽질' 카테고리의 다른 글
| Spring Web의 두 가지 기본 Context (0) | 2023.10.22 |
|---|---|
| Spring Web MVC 동작 과정 (0) | 2023.10.21 |
| @WebMvcTest 옵션으로 특정 클래스 지정하기 (0) | 2023.09.18 |
| JIT과 AOT (0) | 2023.09.15 |
| Arrays.asList()와 ArrayList가 다른 클래스인 이유 (0) | 2023.07.25 |



