1. 카프카를 왜 사용할까요?
설명하기 앞서 단어 두 가지를 정하고 가겠습니다.
이벤트 발생을 하는 곳을 프로듀서(Producer)라 하겠습니다.
발생된 이벤트를 사용하는 곳을 컨슈머(Consumer)라 하겠습니다.
카프카를 사용하기 이전에는 프로듀서와 컨슈머를 연결하는 데이터 파이프라인이 많았습니다.

카프카는 이 문제를 데이터의 중앙화로 해결했습니다.
또한, 그 연결 관계를 느슨하게 합니다.

발생한 이벤트를 카프카에서 낮은 지연(Latency)과 높은 처리량(Throughput)으로 처리할 수 있도록 보장합니다.
또한, 그림과 같이 모든 처리를 분산해서 처리할 수 있도록 합니다.
이러한 이유로 카프라를 분산 이벤트 스트리밍 플랫폼(Distribute Event Streaming Platform)이라 할 수 있습니다.
2. 카프카의 세 가지 주요 기능
카프카는 세 가지 주요 기능을 결합하여 End-to-End 이벤트 스트림으로 구현할 수 있습니다.
- 이벤트 발행 및 구독
- 이벤트를 안정적으로 저장
- 이벤트를 즉시 또는 소급하여 처리
이벤트 발행은 소스에서 하고, 이벤트 구독은 타겟에서 시행하게 됩니다.
카프카에 이벤트가 저장되면, 컨슈머은 원하는 시기에 처리할 수 있습니다.
3. 메시지 큐(Message Queue)
메시지 큐는 비동기로 메시지를 송수신을 할 수 있는 시스템입니다.
카프카는 이벤트 스트리밍 플랫폼이지만, 메시지 브로커의 역할을 하도록 구현하여 사용할 수 있습니다.
즉, 카프카를 메시지 큐처럼 사용할 수 있다는 뜻입니다.
카프카를 사용했을 때 장점은 네 가지가 있습니다.
- 고성능
- 분산 처리로 인한 고가용성 - 클러스터링
- 발행-구독 모델(Push-Pull)
- 영속성 보장
4. 브로커, 토픽, 파티션
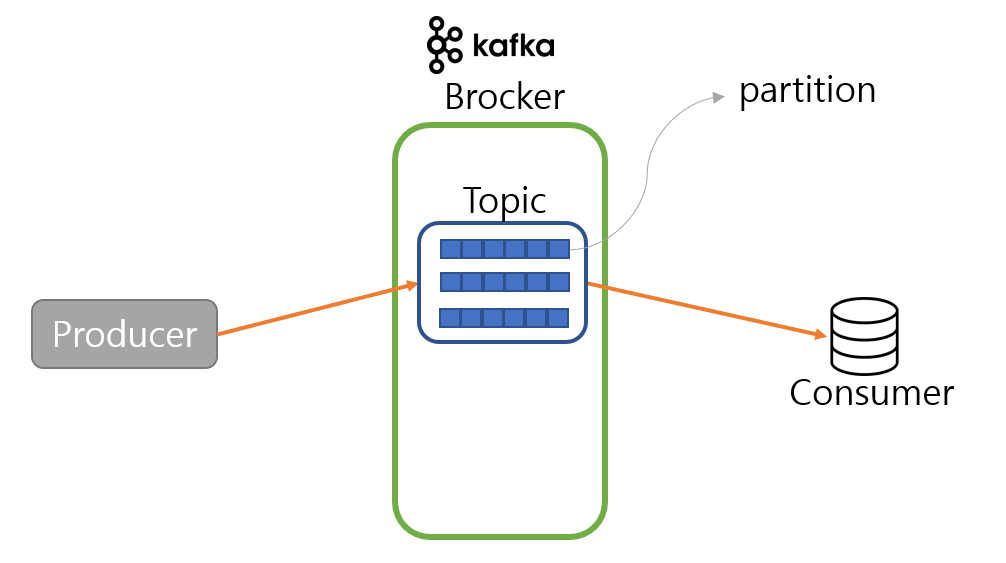
브로커는 프로듀서와 컨슈머가 데이터를 주고 받을수 있게 하는 주체입니다.
브로커는 일반적으로 세 대 이상을 사용하게 됩니다.
여러 브로커에 데이터를 중복저장하여 하나의 브로커가 고장나더라도,
다른 브로커로 대체될 수 있습니다.
토픽은 메시지를 구분하는 단위입니다.
브로커에는 여러 개의 토픽이 있을 수 있습니다.
프로듀서 입장에서는 여러 개의 토픽 중 용도에 맞게 특정 토픽에 데이터를 전송하면 됩니다.
예를들어, 클릭 로그는 클릭 로그에 관한 토픽에 전송하면됩니다.
컨슈머 입장에서는 여러 개의 토픽중 자신이 가져오고 싶은 토픽의 내용만 가져오면 됩니다.
예를들어, 클록 로그라는 토픽에서 데이터를 가져와 클릭 로그를 저장 및 처리할 수 있습니다.
파티션은 토픽 내부의 데이터 저장소입니다.
파티션은 토픽 내부에 있습니다.
토픽 내부에 하나 이상의 파티션이 존재합니다.
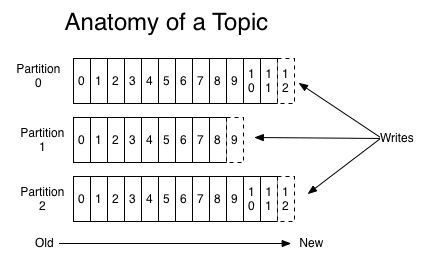
토픽 내부에 파티션이 있는 이유는, 데이터를 병렬처리하기 위함입니다.
병렬처리로 인해 더욱 빠른 속도로 데이터를 처리할 수 있습니다.
조금 더 자세한 내용을 알고 싶으신분은 아래 링크의 영상을 시청해 주시기 바랍니다.
아파치 카프카 | 데이터💾가 저장되는 토픽에 대해서 알아봅시다.
5. 카프카 클러스터, 주키퍼
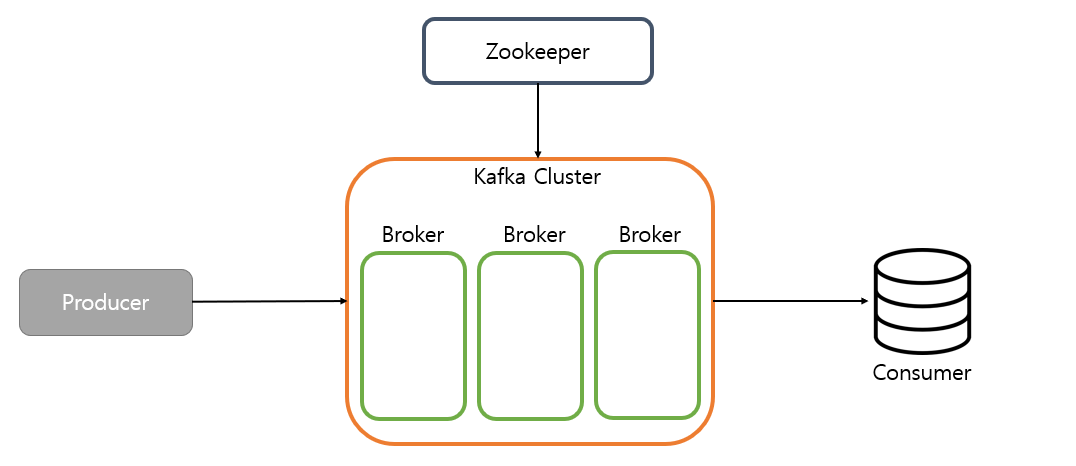
카프카 클러스터는 브로커의 모임입니다.
프로듀서에서 데이터를 받으면, 각 브로커에 데이터를 복제하여 하나의 브로커가 고장나더라도 다른 브로커가 대신하여 동작할 수 있게 합니다.
즉, 고가용성(High Availability)을 높이기 위해 사용됩니다.
주키퍼는 카프카 클러스터를 관리하는 주체입니다.
카프카 클러스터 정보 및 분산처리 관리 등의 메타데이터를 저장합니다.
'카프카' 카테고리의 다른 글
| 카프카 컨슈머 spring boot로 구현하기 (0) | 2023.01.12 |
|---|---|
| 카프카 프로듀서 spring boot로 구현하기 (0) | 2023.01.12 |
| 카프카 프로듀서와 컨슈머 docker shell 에서 테스트하기 (0) | 2023.01.05 |
| 카프카 클러스터 docker compose로 구축하기 (0) | 2023.01.05 |
| 카프카란 무엇인가? - 2 (0) | 2022.12.29 |



